Observabilidade de Dados: Rompendo o Ciclo de Apagar Incêndios
Observabilidade de Dados: Rompendo o Ciclo de Apagar Incêndios
10 de set. de 2024

O profissional de dados que nunca recebeu uma mensagem como essa que atire a primeira pedra!

Antes de mais nada, quero te explicar o por quê isso é um problema maior do que você pensa…
Quando recebemos uma mensagem como essa, estamos gastando o recurso mais escasso que os times de dados possuem: a confiança.
Imagine que o gerente do time comercial (vamos chama-lo de João) nos avisou que o principal dashboard da área dele esta quebrado. O João bem provavelmente tem que dar conta de muita coisa, e por consequência sua agenda é bem apertada. Quando ele acessa algum produto do time de dados ele não só precisa da informação que o dashboard em questão deveria apresentar, mas precisa também tomar alguma ação em cima desta informação. Afinal de contas isso é ser data-driven, certo? Tomar decisões/ações baseados por dados.
Existem ações que podem ser realizadas sem o input de dados, mas outras, como a realização do pagamento de comissões do time comercial, bem provavelmente irão sofrer block até que o time de dados resolva o problema.
Veja que nesta situação hipotética, além de deixar o João “na mão”, interrompemos bruscamente a jornada dele, causando um atrito que ainda pode piorar muito durante o processo de resolução deste ticket, mas isso é papo para outro artigo.
Casos como o do João são recorrentes. De acordo com uma pesquisa feita por Dun & Bradstreet ( The Past, Present and Future of Data ), 42% das empresas já enfrentaram problemas com dados inconsistentes.
Existem inúmeros motivos que resultam em problemas de dados, sendo geralmente agrupados em problemas de regulamentação, demanda de negócio, erro humano, erro de interpretação e data-drift. É importante entendermos estes problemas como algo que acompanha projetos de dados, não incompetência do time ou da solução desenvolvida. Este artigo do google inclusive aponta que existe uma prevalência de 92% de ocorrer um problema de dados em um projeto.
O que torna difícil lidar com estas situações é que, por si só, um conjunto de dados não gera exceptions, por mais errado que este dataset esteja, a inconsistência só será descoberta quando ele é utilizado. Andy Petrella, autor do livro Fundamentals of Data Observability ainda vai além ao chamar dados de “Assasino Silencioso”, uma vez que situações como essa resultam em uma desaceleração geral, destruição da confiança e aumento do estresse, raiva e ansiedade, sem que houvesse qualquer alerta de aviso.
O objetivo da Observabilidade, e deste artigo em específico sobre dados, é informar um observador sobre o status de um sistema. Para isso fazemos uso de 3 principais componentes: logs, traces e métricas, acompanhando a execução das diversas etapas de um pipeline de dados e gerando alertas caso alguma regra não seja respeitada.
No exemplo anterior, quando fomos avisados que o dashboard comercial apresentava inconsistências, para resolver o problema teríamos que sair explorando cada etapa da estrutura de dados até identificar o erro. Será que ele está no dashboard? No Data Warehouse? O ELT funcionou corretamente? São muitas etapas para explorar, porém se utilizarmos os instrumentos de observabilidade conseguimos identificar essas inconsistências antes mesmo dos nossos usuários as notarem.
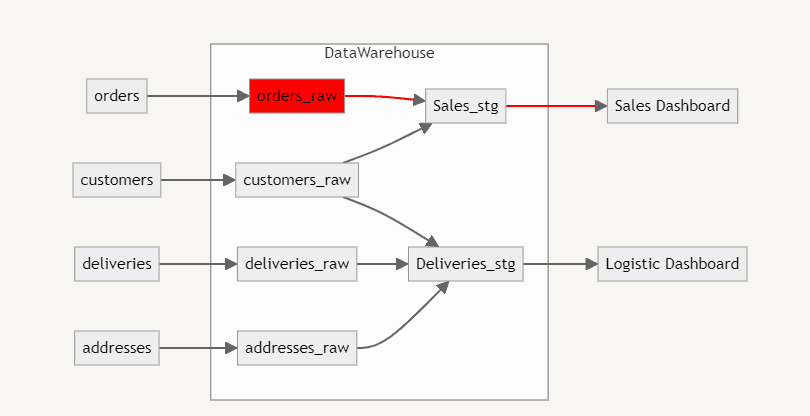
Imagine que você recebeu um alerta que existe inconsistência na tabela orders_raw e por consequência todas as etapas dependentes não serão atualizadas. A partir desta notificação podemos avisar o time que o dashboard de vendas esta desatualizado, além de conseguir dizer uma estimativa para correção. São situações de estresse evitadas puramente por que recebemos um alerta sobre o erro no pipeline de dados.
A principal regra que sempre deve ser seguida na implementação de alertas é que, caso um alerta seja gerado, uma ação deve ser tomada. Quem nunca silenciou um canal de notificações no slack que atire a primeira pedra (estamos ficando sem pedras já hahaha).
Seguir esta regra garante que os alertas não sejam vistos como algo negativo pelo time, e sim como um canal de informação crítica para a operação de dados. Existem várias ferramentas que podem ser usadas para facilitar a implementação de observabilidade em pipelines de dados: o DBT possui vários recursos como os testes e o recém lançado teste unitário da (disponível na v.18). Outra solução que permite monitoramento é o great expectations que permite a construção de contratos de dados e gera um alerta caso algum destes seja violado.
Esperamos que o conteúdo tenha contribuído de alguma forma! Se quiser saber mais sobre a Erathos, teste a plataforma gratuitamente aqui!
O profissional de dados que nunca recebeu uma mensagem como essa que atire a primeira pedra!
Antes de mais nada, quero te explicar o por quê isso é um problema maior do que você pensa…
Quando recebemos uma mensagem como essa, estamos gastando o recurso mais escasso que os times de dados possuem: a confiança.
Imagine que o gerente do time comercial (vamos chama-lo de João) nos avisou que o principal dashboard da área dele esta quebrado. O João bem provavelmente tem que dar conta de muita coisa, e por consequência sua agenda é bem apertada. Quando ele acessa algum produto do time de dados ele não só precisa da informação que o dashboard em questão deveria apresentar, mas precisa também tomar alguma ação em cima desta informação. Afinal de contas isso é ser data-driven, certo? Tomar decisões/ações baseados por dados.
Existem ações que podem ser realizadas sem o input de dados, mas outras, como a realização do pagamento de comissões do time comercial, bem provavelmente irão sofrer block até que o time de dados resolva o problema.
Veja que nesta situação hipotética, além de deixar o João “na mão”, interrompemos bruscamente a jornada dele, causando um atrito que ainda pode piorar muito durante o processo de resolução deste ticket, mas isso é papo para outro artigo.
Casos como o do João são recorrentes. De acordo com uma pesquisa feita por Dun & Bradstreet ( The Past, Present and Future of Data ), 42% das empresas já enfrentaram problemas com dados inconsistentes.
Existem inúmeros motivos que resultam em problemas de dados, sendo geralmente agrupados em problemas de regulamentação, demanda de negócio, erro humano, erro de interpretação e data-drift. É importante entendermos estes problemas como algo que acompanha projetos de dados, não incompetência do time ou da solução desenvolvida. Este artigo do google inclusive aponta que existe uma prevalência de 92% de ocorrer um problema de dados em um projeto.
O que torna difícil lidar com estas situações é que, por si só, um conjunto de dados não gera exceptions, por mais errado que este dataset esteja, a inconsistência só será descoberta quando ele é utilizado. Andy Petrella, autor do livro Fundamentals of Data Observability ainda vai além ao chamar dados de “Assasino Silencioso”, uma vez que situações como essa resultam em uma desaceleração geral, destruição da confiança e aumento do estresse, raiva e ansiedade, sem que houvesse qualquer alerta de aviso.
O objetivo da Observabilidade, e deste artigo em específico sobre dados, é informar um observador sobre o status de um sistema. Para isso fazemos uso de 3 principais componentes: logs, traces e métricas, acompanhando a execução das diversas etapas de um pipeline de dados e gerando alertas caso alguma regra não seja respeitada.
No exemplo anterior, quando fomos avisados que o dashboard comercial apresentava inconsistências, para resolver o problema teríamos que sair explorando cada etapa da estrutura de dados até identificar o erro. Será que ele está no dashboard? No Data Warehouse? O ELT funcionou corretamente? São muitas etapas para explorar, porém se utilizarmos os instrumentos de observabilidade conseguimos identificar essas inconsistências antes mesmo dos nossos usuários as notarem.
Imagine que você recebeu um alerta que existe inconsistência na tabela orders_raw e por consequência todas as etapas dependentes não serão atualizadas. A partir desta notificação podemos avisar o time que o dashboard de vendas esta desatualizado, além de conseguir dizer uma estimativa para correção. São situações de estresse evitadas puramente por que recebemos um alerta sobre o erro no pipeline de dados.
A principal regra que sempre deve ser seguida na implementação de alertas é que, caso um alerta seja gerado, uma ação deve ser tomada. Quem nunca silenciou um canal de notificações no slack que atire a primeira pedra (estamos ficando sem pedras já hahaha).
Seguir esta regra garante que os alertas não sejam vistos como algo negativo pelo time, e sim como um canal de informação crítica para a operação de dados. Existem várias ferramentas que podem ser usadas para facilitar a implementação de observabilidade em pipelines de dados: o DBT possui vários recursos como os testes e o recém lançado teste unitário da (disponível na v.18). Outra solução que permite monitoramento é o great expectations que permite a construção de contratos de dados e gera um alerta caso algum destes seja violado.
Esperamos que o conteúdo tenha contribuído de alguma forma! Se quiser saber mais sobre a Erathos, teste a plataforma gratuitamente aqui!
O profissional de dados que nunca recebeu uma mensagem como essa que atire a primeira pedra!
Antes de mais nada, quero te explicar o por quê isso é um problema maior do que você pensa…
Quando recebemos uma mensagem como essa, estamos gastando o recurso mais escasso que os times de dados possuem: a confiança.
Imagine que o gerente do time comercial (vamos chama-lo de João) nos avisou que o principal dashboard da área dele esta quebrado. O João bem provavelmente tem que dar conta de muita coisa, e por consequência sua agenda é bem apertada. Quando ele acessa algum produto do time de dados ele não só precisa da informação que o dashboard em questão deveria apresentar, mas precisa também tomar alguma ação em cima desta informação. Afinal de contas isso é ser data-driven, certo? Tomar decisões/ações baseados por dados.
Existem ações que podem ser realizadas sem o input de dados, mas outras, como a realização do pagamento de comissões do time comercial, bem provavelmente irão sofrer block até que o time de dados resolva o problema.
Veja que nesta situação hipotética, além de deixar o João “na mão”, interrompemos bruscamente a jornada dele, causando um atrito que ainda pode piorar muito durante o processo de resolução deste ticket, mas isso é papo para outro artigo.
Casos como o do João são recorrentes. De acordo com uma pesquisa feita por Dun & Bradstreet ( The Past, Present and Future of Data ), 42% das empresas já enfrentaram problemas com dados inconsistentes.
Existem inúmeros motivos que resultam em problemas de dados, sendo geralmente agrupados em problemas de regulamentação, demanda de negócio, erro humano, erro de interpretação e data-drift. É importante entendermos estes problemas como algo que acompanha projetos de dados, não incompetência do time ou da solução desenvolvida. Este artigo do google inclusive aponta que existe uma prevalência de 92% de ocorrer um problema de dados em um projeto.
O que torna difícil lidar com estas situações é que, por si só, um conjunto de dados não gera exceptions, por mais errado que este dataset esteja, a inconsistência só será descoberta quando ele é utilizado. Andy Petrella, autor do livro Fundamentals of Data Observability ainda vai além ao chamar dados de “Assasino Silencioso”, uma vez que situações como essa resultam em uma desaceleração geral, destruição da confiança e aumento do estresse, raiva e ansiedade, sem que houvesse qualquer alerta de aviso.
O objetivo da Observabilidade, e deste artigo em específico sobre dados, é informar um observador sobre o status de um sistema. Para isso fazemos uso de 3 principais componentes: logs, traces e métricas, acompanhando a execução das diversas etapas de um pipeline de dados e gerando alertas caso alguma regra não seja respeitada.
No exemplo anterior, quando fomos avisados que o dashboard comercial apresentava inconsistências, para resolver o problema teríamos que sair explorando cada etapa da estrutura de dados até identificar o erro. Será que ele está no dashboard? No Data Warehouse? O ELT funcionou corretamente? São muitas etapas para explorar, porém se utilizarmos os instrumentos de observabilidade conseguimos identificar essas inconsistências antes mesmo dos nossos usuários as notarem.
Imagine que você recebeu um alerta que existe inconsistência na tabela orders_raw e por consequência todas as etapas dependentes não serão atualizadas. A partir desta notificação podemos avisar o time que o dashboard de vendas esta desatualizado, além de conseguir dizer uma estimativa para correção. São situações de estresse evitadas puramente por que recebemos um alerta sobre o erro no pipeline de dados.
A principal regra que sempre deve ser seguida na implementação de alertas é que, caso um alerta seja gerado, uma ação deve ser tomada. Quem nunca silenciou um canal de notificações no slack que atire a primeira pedra (estamos ficando sem pedras já hahaha).
Seguir esta regra garante que os alertas não sejam vistos como algo negativo pelo time, e sim como um canal de informação crítica para a operação de dados. Existem várias ferramentas que podem ser usadas para facilitar a implementação de observabilidade em pipelines de dados: o DBT possui vários recursos como os testes e o recém lançado teste unitário da (disponível na v.18). Outra solução que permite monitoramento é o great expectations que permite a construção de contratos de dados e gera um alerta caso algum destes seja violado.
Esperamos que o conteúdo tenha contribuído de alguma forma! Se quiser saber mais sobre a Erathos, teste a plataforma gratuitamente aqui!
O profissional de dados que nunca recebeu uma mensagem como essa que atire a primeira pedra!
Antes de mais nada, quero te explicar o por quê isso é um problema maior do que você pensa…
Quando recebemos uma mensagem como essa, estamos gastando o recurso mais escasso que os times de dados possuem: a confiança.
Imagine que o gerente do time comercial (vamos chama-lo de João) nos avisou que o principal dashboard da área dele esta quebrado. O João bem provavelmente tem que dar conta de muita coisa, e por consequência sua agenda é bem apertada. Quando ele acessa algum produto do time de dados ele não só precisa da informação que o dashboard em questão deveria apresentar, mas precisa também tomar alguma ação em cima desta informação. Afinal de contas isso é ser data-driven, certo? Tomar decisões/ações baseados por dados.
Existem ações que podem ser realizadas sem o input de dados, mas outras, como a realização do pagamento de comissões do time comercial, bem provavelmente irão sofrer block até que o time de dados resolva o problema.
Veja que nesta situação hipotética, além de deixar o João “na mão”, interrompemos bruscamente a jornada dele, causando um atrito que ainda pode piorar muito durante o processo de resolução deste ticket, mas isso é papo para outro artigo.
Casos como o do João são recorrentes. De acordo com uma pesquisa feita por Dun & Bradstreet ( The Past, Present and Future of Data ), 42% das empresas já enfrentaram problemas com dados inconsistentes.
Existem inúmeros motivos que resultam em problemas de dados, sendo geralmente agrupados em problemas de regulamentação, demanda de negócio, erro humano, erro de interpretação e data-drift. É importante entendermos estes problemas como algo que acompanha projetos de dados, não incompetência do time ou da solução desenvolvida. Este artigo do google inclusive aponta que existe uma prevalência de 92% de ocorrer um problema de dados em um projeto.
O que torna difícil lidar com estas situações é que, por si só, um conjunto de dados não gera exceptions, por mais errado que este dataset esteja, a inconsistência só será descoberta quando ele é utilizado. Andy Petrella, autor do livro Fundamentals of Data Observability ainda vai além ao chamar dados de “Assasino Silencioso”, uma vez que situações como essa resultam em uma desaceleração geral, destruição da confiança e aumento do estresse, raiva e ansiedade, sem que houvesse qualquer alerta de aviso.
O objetivo da Observabilidade, e deste artigo em específico sobre dados, é informar um observador sobre o status de um sistema. Para isso fazemos uso de 3 principais componentes: logs, traces e métricas, acompanhando a execução das diversas etapas de um pipeline de dados e gerando alertas caso alguma regra não seja respeitada.
No exemplo anterior, quando fomos avisados que o dashboard comercial apresentava inconsistências, para resolver o problema teríamos que sair explorando cada etapa da estrutura de dados até identificar o erro. Será que ele está no dashboard? No Data Warehouse? O ELT funcionou corretamente? São muitas etapas para explorar, porém se utilizarmos os instrumentos de observabilidade conseguimos identificar essas inconsistências antes mesmo dos nossos usuários as notarem.
Imagine que você recebeu um alerta que existe inconsistência na tabela orders_raw e por consequência todas as etapas dependentes não serão atualizadas. A partir desta notificação podemos avisar o time que o dashboard de vendas esta desatualizado, além de conseguir dizer uma estimativa para correção. São situações de estresse evitadas puramente por que recebemos um alerta sobre o erro no pipeline de dados.
A principal regra que sempre deve ser seguida na implementação de alertas é que, caso um alerta seja gerado, uma ação deve ser tomada. Quem nunca silenciou um canal de notificações no slack que atire a primeira pedra (estamos ficando sem pedras já hahaha).
Seguir esta regra garante que os alertas não sejam vistos como algo negativo pelo time, e sim como um canal de informação crítica para a operação de dados. Existem várias ferramentas que podem ser usadas para facilitar a implementação de observabilidade em pipelines de dados: o DBT possui vários recursos como os testes e o recém lançado teste unitário da (disponível na v.18). Outra solução que permite monitoramento é o great expectations que permite a construção de contratos de dados e gera um alerta caso algum destes seja violado.
Esperamos que o conteúdo tenha contribuído de alguma forma! Se quiser saber mais sobre a Erathos, teste a plataforma gratuitamente aqui!